Kubernetes 基础平台的应用搭建
前言
之前在《JupyterLab 的搭建与运维》一文中,尝试了在单机上搭建部署 JupyterHub。不得不说,的确方便了团队内部共同使用同一台 GPU 服务器。但也有比较大的限制:
- 运行中的实例对于 CPU、GPU、内存、硬盘等资源完全共享。当所有用户都申请的资源总和超出服务器所拥有的资源时,任务的运行效率将会大打折扣。甚至可能会容易出现內存溢出的问题,造成宿主机出现 BUG。
- 难以同时管理多台服务器。在有多台不同 CPU/GPU 服务器时,单机部署的方案会造成多个入口,且很难实现用户数据在多机间的实时同步。
- 资源回收和重置存在一定的难度。在单机部署方案中虽然也可以通过 JupyterHub 来限制闲置时间不超过多久,但是实例只会被关闭,而非销毁。如果用户实例出现了某些未知的配置问题,只能依靠管理员手动销毁实例来解决。
其实,JupyterHub 官方很早就意识到了这些,并通过拥抱 Kubernetes (以下简称“K8S”)来解决以上限制。可以说 K8S 天然是为 JupyterHub 多机资源管理调度而生,可以:
- 对运行实例的资源进行严格地限制,防止运行实例申请资源总和超出节点资源。
- 根据集群实际运行情况来自动分布部署运行实例,在具有很大的节点池的情况下非常有效。
- 共享持久化存储,平稳迁移运行实例到任一节点,自由切换 CPU/GPU 节点。
- 自动销毁超过一定闲置时间的实例,并且在每次启动运行实例时都会拉取最新镜像。
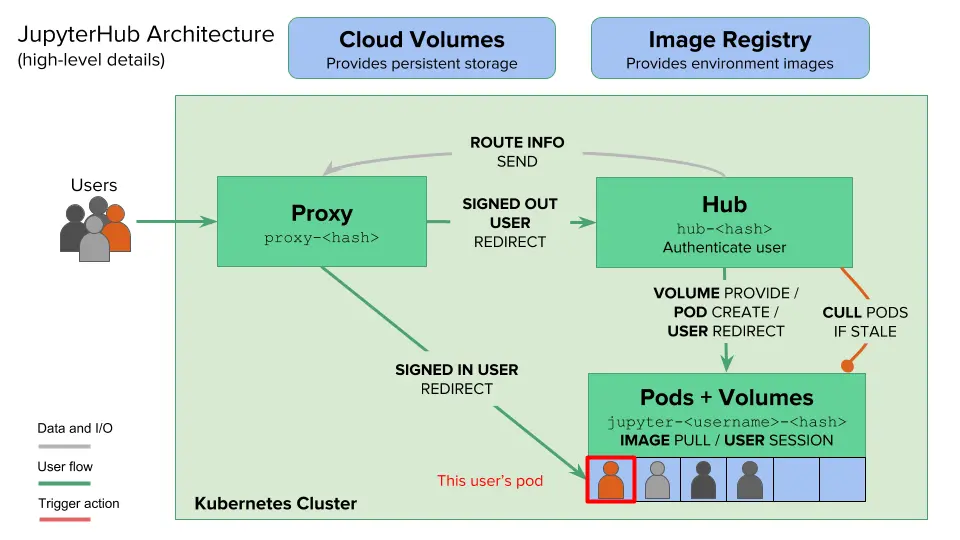
搭建
这里我们以一个简单的 CPU/GPU 科学计算集群为例:
- 登录节点 l0:提供服务入口(Web)
- CPU/GPU 共用节点 l1、l2:运行实例部署池(可以根据实际情况和需求扩充或缩小)
- 存储节点 nas:提供持久化存储(独立存储方案优于登录节点 NFS 服务)
网络规划
以下为集群节点对应的 IP 地址信息:
| 节点主机名 | IP 地址 | 备注 |
|---|---|---|
| l0 | 192.168.120.100 | 登录节点,K8S 控制节点 |
| l1 | 192.168.120.101 | CPU/GPU 节点,K8S 工作节点 |
| l2 | 192.168.120.102 | CPU/GPU 节点,K8S 工作节点 |
| nas | 192.168.120.99 | 存储节点,NFS 服务 |
K8S 集群节点子网为 192.168.120.0/24。另外Pod 子网设置为 192.168.144.0/20、Service 子网设置为 192.168.244.0/20。
K8S 集群搭建
集群搭建过程请见《Kubernetes 不完全入门》一文,需配置好节点识别 NVIDIA 显卡和 NFS CSI 存储。
Helm 部署 JupyterHub
安装 Helm
类似于操作系统的 APT 等包管理器,Helm 是 Kubernetes 的包管理器,一般定义了部署在 K8S 集群中的应用所需的所有配置文件。
Helm 可以通过系统包管理工具安装或者直接下载二进制文件使用。Ubuntu 系统如下操作:
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
sudo apt-get install apt-transport-https --yes
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm -y
二进制文件请自行前往 https://github.com/helm/helm/releases 下载。
添加 Chart
Chart 是 Helm 使用的包格式,可以被认为是“软件源中的软件名”(实际是多种软件的集合)。这主要是因为如果要编写部署一整套应用所需的配置文件实在太复杂、耗时了,使用 Chart 只需要写一个自定义配置文件来覆盖想要修改的默认配置即可。
helm repo add jupyterhub https://hub.jupyter.org/helm-chart/
helm repo update
准备自定义配置文件
自定义配置文件可以是任意文件名,但必须是 yaml 格式,比如 config.yaml。对于以下配置我们可能需要进行自定义:
-
对外代理服务:一般来说,JupyterHub 只有 Web 访问端口需要由 K8S 集群在控制节点暴露给反向代理服务(比如 Nginx)。这里的
proxy.service.nodePorts.http配置为34567端口。另外,我们可以将proxy.chp.networkPolicy.enabled置为false来取消 K8S 网络限制。为了安全,在1.0.0版本之前也许手动设置proxy.secretToken字段(使用openssl rand -hex 32命令生成)。 -
hub 配置:(1)设置
hub.networkPolicy.enabled为false取消网络限制;(2)(可选)使用hub.extraVolumes字段来添加指定的持久化卷名;(3)(可选,推荐)配置hub.config来启用 Oauth2 认证登录,目前官方支持 Github、Gitlab 在内的多款认证方式,详细请见 The OAuthenticator。这里我们使用自建 Gitlab 来测试。 -
全局配置:(1)(可选)可以修改
prePuller.hook.enabled为false来禁用节点预拉取运行实例镜像。启用的情况下,当有新节点加入可用集群时可以自动拉取,以避免第一次在新节点部署实例时用户需要等待一段时间。(2)(可选)限制实例最长可运行时间cull.maxAge和最长闲置时间cull.timeout,通过自动销毁来提升集群的可用率。cull.enabled字段也需要置为true从而生效。cull.every字段可以设置每分钟检查是否超出限制。 -
用户实例配置:(1)NFS 持久化,通过设置
singleuser.extraPodConfig.securityContext中的fsGroup(值为100) 和fsGroupChangePolicy(值为OnRootMismatch) 来实现启动实例跳过每次修改文件夹权限,仅当文件夹父目录不为root用户 (id 为100) 拥有时才会修改文件夹权限。(2)基本配置,包括网络策略、环境变量、启动超时最长限制(即最长等待启动时间)。(3)动态存储卷配置,设置singleuser.storage.dynamic.storageClass为nfs-csi来启用自动动态存储卷,可以用singleuser.storage.capacity来设置默认卷大小限制。由于实例中默认的缓冲区较小,在內存有限的情况下某些任务可能用缓冲区,因此可以挂载较大的本地临时卷来充当/dev/shm和/dev/fuse。(4)可用资源配置方案,相比单机部署的单一选择,K8S 部署方案可以提供多样化的资源配置方案,不仅包括 CPU、内存资源的集合,还有 GPU 资源。甚至于还可以通过 K8S 的节点标签来由用户手动选择哪个节点(当然仅在资源满足的情况下会成功创建)。
以下为一个样例:
proxy:
chp:
networkPolicy:
enabled: false
service:
nodePorts:
http: 34567
secretToken: "<GENERATE SECRET TOKEN BY YOURSELF>"
hub:
networkPolicy:
enabled: false
extraVolumes:
- name: hub-db-dir
persistentVolumeClaim:
claimName: hub-db-dir
config:
JupyterHub:
authenticator_class: oauthenticator.gitlab.GitLabOAuthenticator
GitLabOAuthenticator:
client_id: "<COPY IT FROM YOUR OAUTH2 SERVER>"
client_secret: "<COPY IT FROM YOUR OAUTH2 SERVER>"
oauth_callback_url: "https://jupyter.lisz.me/hub/oauth_callback"
gitlab_url: "https://git.lisz.me"
login_service: "Gitlab"
scope:
- read_user
- read_api
- api
- openid
- profile
- email
admin_users:
- <adminer_username>
allowed_gitlab_groups:
- <group_name>
prePuller:
hook:
enabled: false
cull:
enabled: true
maxAge: 172800
timeout: 600
every: 60
singleuser:
extraPodConfig:
securityContext:
fsGroup: 100
fsGroupChangePolicy: "OnRootMismatch"
networkPolicy:
enabled: false
extraEnv:
EDITOR: "vim"
SHELL: "/bin/zsh"
PYTHONUNBUFFERED: "1"
startTimeout: 300
storage:
capacity: 100Gi
dynamic:
storageClass: nfs-csi
extraVolumes:
- name: shm-volume
emptyDir:
medium: Memory
sizeLimit: "20Gi"
- name: fuse-device
hostPath:
path: /dev/fuse
type: CharDevice
extraVolumeMounts:
- name: shm-volume
mountPath: /dev/shm
- name: fuse-device
mountPath: /dev/fuse
image:
name: quay.io/zhonger/base-notebook
tag: v3
pullPolicy: Always
profileList:
- display_name: "CPU 分区"
description: '包含 Conda、Python 环境(8核16G)'
default: true
kubespawner_override:
cpu_gurantee: 1
memo_gurantee: "1G"
cpu_limit: 8
mem_limit: "16G"
profile_options:
image:
display_name: "主机"
choices:
lab6:
display_name: "l1"
kubespawner_override:
node_selector: {'kubernetes.io/hostname': 'l1'}
lab9:
display_name: "l2"
kubespawner_override:
node_selector: {'kubernetes.io/hostname': 'l2'}
- display_name: "GPU 分区"
description: "包含 Conda、Python、CUDA 环境(8核16G)"
kubespawner_override:
image: quay.io/zhonger/gpu-notebook:v3
image_pull_policy: Always
cpu_gurantee: 1
mem_gurantee: "1G"
cpu_limit: 8
mem_limit: "16G"
profile_options:
image:
display_name: "资源配置"
choices:
A100x1:
display_name: "A100 (Python 3.11, CUDA 12) GPU x1"
kubespawner_override:
node_selector: {'gputype': 'A100'}
extra_resource_limits:
nvidia.com/gpu: "1"
P100x1:
display_name: "P100 (Python 3.11, CUDA 12) GPU x1"
kubespawner_override:
node_selector: {'gputype': 'P100'}
extra_resource_limits:
nvidia.com/gpu: "1"
如果用标签来选择节点的话,需要通过类似 kubectl label node l1 gputype=A100 命令预先配置好标签。
启动 JupyterHub
准备好以上配置文件后,可以使用以下命令启动。
helm upgrade --cleanup-on-fail \
--install <helm-release-name> jupyterhub/jupyterhub \
--namespace <k8s-namespace> \
--create-namespace \
--version=<chart-version> \
--values config.yaml
建议先下载好 JupyterHub 所需的镜像,可以通过 helm show values jupyterhub 来查看所有的镜像列表。或者可以用 helm pull jupyterhub/jupyterhub --version 4.2.0 来下载原始 Chart 文件,解压后查看 values.yaml 文件即可。如果想要使用国内镜像的话,就修改 values.yaml 文件里的镜像名再启动 JupyterHub。这里可以用本地的文件夹名称或压缩包名称来替代 jupyterhub/jupyterhub 。
配置 Nginx
当 JupyterHub 启动后,默认用户还是无法从本地访问服务器上部署的 JupyterHub 的,还需要使用 Nginx 代理一下。以下是 Nginx 虚拟主机配置样例。这样一来,就可以在用户端通过域名来直接访问部署好的 JupyterHub 了。
server {
listen 443 ssl;
server_name jupyter.lisz.me;
ssl_certificate /home/ubuntu/ssl/jupyter.lisz.me.cert.pem;
ssl_certificate_key /home/ubuntu/ssl/jupyter.lisz.me.key.pem;
# SSL settings (optional but recommended)
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
client_max_body_size 10G;
# Logging
access_log /var/log/nginx/jupyter_access.log;
error_log /var/log/nginx/jupyter_error.log;
location / {
proxy_pass http://localhost:30000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# WebSocket support
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
# Redirect HTTP to HTTPS
server {
listen 80;
server_name jupyter.lisz.me;
return 301 https://$host$request_uri;
}
JupyterHub 的 proxy 本身也可以提供对外访问的 HTTPS,详见 JupyterHub for Kubernetes – Administrator Guide/Security/HTTPS。其他反向代理软件也都适用。
由于 proxy 配置使用了 nodePorts 来创建端口映射,默认是可以在其他节点访问到指定的端口的。如果想要仅允许 Nginx 代理所在主机访问,可以通过 ingress 来支持更精细的访问控制,详见 JupyterHub for Kubernetes – Resources/ingress。
运维
基本管理
部署完成后,我们需要通过 K8S 的 kubectl 命令来查看、管理 JupyterHub 应用。以下为一些常见的命令:
## 假设为 JupyterHub 创建的 namespace 为 jhub
# 查看 JupyterHub 所有 Pod 状态
╰─$ kubectl get pod -n jhub
NAME READY STATUS RESTARTS AGE
continuous-image-puller-76bkq 1/1 Running 0 5d1h
continuous-image-puller-hntww 1/1 Running 0 5d1h
hub-6867b9b6c7-slg9c 1/1 Running 0 5d1h
proxy-cc45cd6f6-g2t24 1/1 Running 0 5d1h
user-scheduler-7b465896b-bq4l6 1/1 Running 0 5d1h
user-scheduler-7b465896b-rvqgx 1/1 Running 0 5d1h
# 查看节点资源使用情况
╰─$ kubectl describe node l1
# 查看用户实例状态或启动问题
╰─$ kubectl descirbe -n jhub pod jupyter-zhonger
# 查看用户动态存储卷情况
╰─$ kubectl get -n jhub pvc
备份和恢复存储卷
由于使用动态存储卷,卷配置显得尤为重要。(毕竟 NFS 存储在远端,独立于 K8S 集群。)可以通过以下命令备份和恢复存储卷。
# 备份所有 PV 和 PVC
kubectl get pv -o yaml > all_pvs.yaml
kubectl get pvc --all-namespaces -o yaml > all_pvc_by_namespace.yaml
# 从备份文件中恢复所有 PV 和 PVC
kubectl apply -f all_pvs.yaml
kubectl apply -f all_pvc_by_namespace.yaml
更改存储卷大小
从查阅的资料来看,NFS 存储是无法动态更新存储卷大小的。换句话说,重新定义存储卷就可以手动更改存储大小。举个例子,现在想要为用户 zhonger 从默认的存储卷大小 100G 更改到 1T。那么我们先要获得用户 zhonger 的存储卷配置文件 pvc 和 pv。
# 保存 PVC 配置到 YAML 文件
kubectl get pvc claim-zhonger -n jhub -o yaml > claim-zhonger-pvc.yaml
# 从 claim-zhonger-pvc.yaml 获知 PV_NAME
kubectl get pv <PV_NAM> -o yaml > claim-zhonger-pv.yaml
# 确保实例已经被销毁后,删除 PVC 和 PV
kubectl delete -f claim-zhonger-pvc.yaml
kubectl delete -f claim-zhonger-pv.yaml
# 修改存储卷大小
sed -i "s/100Gi/1Ti/" claim-zhonger-*.yaml
# 重新定义存储卷
kubectl apply -f claim-zhonger-pv.yaml
kubectl apply -f claim-zhonger-pvc.yaml
这里需要注意的是,PV 和 PVC 之间的依赖关系。PV 是先定义的,不属于任何命名空间。PVC 是依托于 PV 定义的,必须属于某个命名空间。所以删除的时候要先 PVC 再 PV,定义的时候要先 PV 再 PVC。
资源配置方案
对于资源配置方案,我们可以根据镜像、CPU 核数、内存大小、GPU 块数的不同来创建出多样化方案。可以参考 Amazon 提供的丰富示例 jupyterhub-values-dummy.yaml 了解更多。
利用情况监控与统计
目前可以使用 Grafana + Prometheus 的方式来对 K8S 集群中所有的资源利用情况进行监控,也可以自行设计一个 Grafana 面板来展示当前 JupyterHub 应用中启动的用户实例情况。但对于更加进一步详细、细致的监控与统计还有待设计(类似于“单个用户的利用报告”、“全平台的利用报告”等)。
总结
JupyterHub 在 K8S 平台上散发出越来越强大的魅力,使得研究团队搭建自己的科学计算平台越来越容易。当然目前依然还是有一些挑战,比如“多节点 GPU 的调用”。类似于“机器学习模型训练任务”通常需要调试后再放在大规模的 GPU 集群上训练,而 JupyterHub 长于调试代码,是否可以调试完成后直接提交给更大规模的 GPU 集群后台计算呢?
参考资料
- JupyterHub for Kubernetes – Installation
- Let pod’s securityContext fsGroupChangePolicy default to OnRootMismatch?
- Building multi-tenant JupyterHub Platforms on Amazon EKS
版权声明: 如无特别声明,本文版权归 仲儿的自留地 所有,转载请注明本文链接。
(采用 CC BY-NC-SA 4.0 许可协议进行授权)
本文标题:《 Kubernetes 应用之 JupyterHub 搭建和运维 》
本文链接:https://lisz.me/tech/k8s/k8s-jupyterhub.html
本文最后一次更新为 天前,文章中的某些内容可能已过时!

Developer & Maintainer

